Latest TTS Architecture and differences | 2026
Text To Speech Models
Exploring the latest and unique tts papers.
Seed TTS
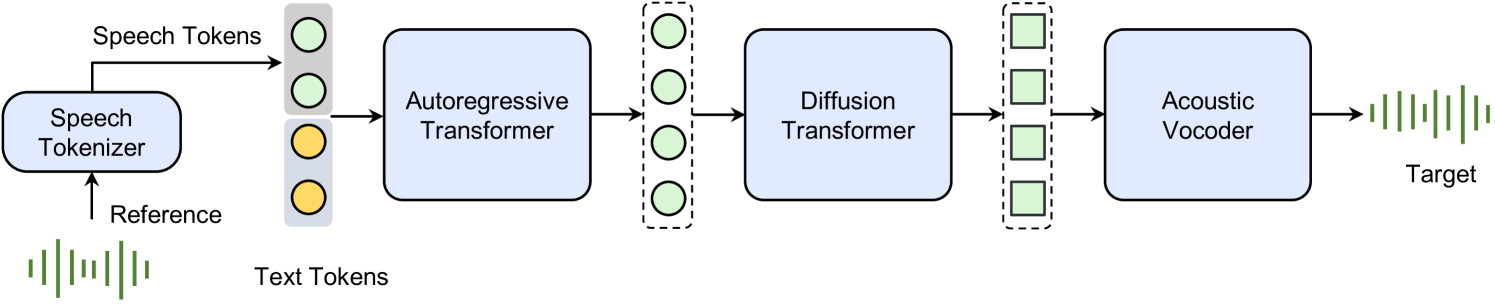
Three unique contributions:
- Self-distillation for voice conversion — generates pairs of speech with same content/prosody but different timbre, then trains to disentangle them. No special loss functions needed.
- RL post-training (REINFORCE) — uses WER + SIM as rewards, dramatically improves robustness and emotion control
- Seed-TTSDiT — a fully diffusion-based variant (no LM) that enables speech editing (change one word without re-recording everything)
Note
One key insight about RL they discovered: Lower WER doesn’t always mean better speech — the model learns to speak more “standardized” but less natural. Classic reward hacking.
Spark TTS
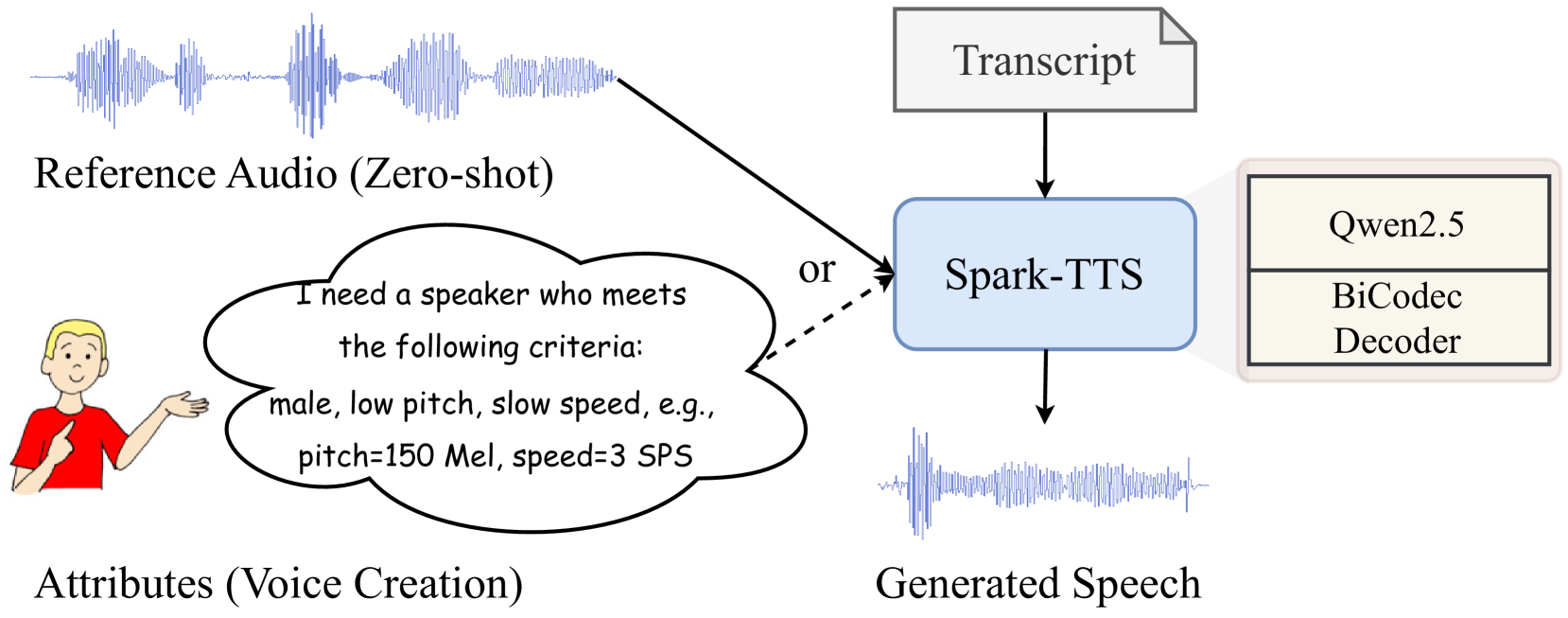 It’s an efficient TTS system built on a standard text LLM (Qwen2.5), powered by BiCodec : a novel codec that separates content from speaker identity in a fundamentally different way than all other papers.
It’s an efficient TTS system built on a standard text LLM (Qwen2.5), powered by BiCodec : a novel codec that separates content from speaker identity in a fundamentally different way than all other papers.
What is BiCodec ?
| Token Type | Count | Captures |
|---|---|---|
| Semantic tokens | 50/second | What is said (content, rhythm) |
| Global tokens | 32 total per clip | Who is speaking (voice identity) |
Compare to everyone else who uses 12–50 tokens/second carrying mixed semantic+acoustic info.
BiCodec’s global tokens are time-invariant — they describe the whole voice, not individual frames.
Question
what if this chunk has missed feelings at same time would global tokens catches these?
Why this matters: The LM only predicts semantic tokens + 32 global tokens.
No multi-codebook complexity.
Plugs directly into any standard text LLM.
Voice Creation via Chain-of-Thought
Because speaker identity is isolated in 32 global tokens, you can describe a voice:
"Female, high pitch, fast speed"
→ LM predicts fine-grained pitch/speed values
→ LM predicts 32 global tokens (voice identity)
→ LM predicts semantic tokens (content)
→ BiCodec decoder → audioNo reference audio needed
VoxBox Dataset
- 100K hours, English + Chinese
- Annotated with gender, pitch, speaking rate, age, emotion
- Fully open source — fills a major gap in the field
Spark tts Performance
On Seed-TTS benchmark (WER ↓):
| Model | Chinese CER | English WER |
|---|---|---|
| Seed-TTS | 1.12% | 2.25% |
| F5-TTS | 1.56% | 1.83% |
| Spark-TTS | 1.20% | 1.98% |
| Llasa-8B (8x bigger!) | 1.59% | 2.97% |
Spark-TTS beats an 8B model with only 0.5B parameters. #ai/voice/tts/paper
Inworld TTS-1 Paper — Study Notes
What is Inworld TTS AI
Inworld AI built two LLM-based text-to-speech models:
- TTS-1 (1.6B params) — fast, real-time, on-device
- TTS-1-Max (8.8B params) — higher quality, demanding applications
Both support 11 languages, 48 kHz audio, voice cloning from a short clip, and emotional control.
Inworld TTS Architecture
- An audio codec converts raw audio ↔︎ discrete tokens (like JPEG for audio)
- A SpeechLM (LLaMA backbone) generates audio tokens from text + reference audio
- The codec decoder reconstructs the final waveform from those tokens
Inworld TTS Training Pipeline
Three stages, same recipe as modern LLMs:
- Pre-training — ~1M hours of raw audio, unsupervised next-token prediction
- SFT — ~200k hours of clean filtered audio, supervised imitation
- RL alignment (GRPO) — rewards-based optimization toward human-preferred output
Inworld TTS GRPO & RL Alignment
- Generate 8 outputs per input, score each, reward the above-average ones
- Reward = weighted combination of:
- WER — did it say the right words? (via Whisper)
- Speaker Similarity (SIM) — does it sound like the reference voice? (via WavLM embeddings + cosine similarity)
- DNSMOS — does it sound clean/natural? (neural MOS predictor)
Audio Codec & 48 kHz
- Codec bridges raw audio and LLM-friendly tokens
- 48 kHz = 48,000 samples/sec → richer high-frequency detail than 16/24 kHz
- They confirmed 48 kHz gave better DNSMOS scores
Inworld TTS Streaming Tricks
Two problems when concatenating audio chunks in real-time:
- Clicks at boundaries → solved by only cutting at natural silence points
- Volume jumps → solved by feeding decoder extra context, then trimming overlap
Inworld TTS Limitations (especially for Arabic)
- WavLM (SIM) and DNSMOS were trained mostly on English data
- Reward signals are unreliable for underrepresented languages
- Arabic is not among the 11 supported languages
- RL could make things worse if the reward model doesn’t understand the language
Key Metrics to Know for TTS
| Metric | What it measures | Better = |
|---|---|---|
| WER | Word error rate | Lower |
| SIM | Speaker similarity | Higher |
| DNSMOS | Perceptual audio quality | Higher |
Qwen3-TTS
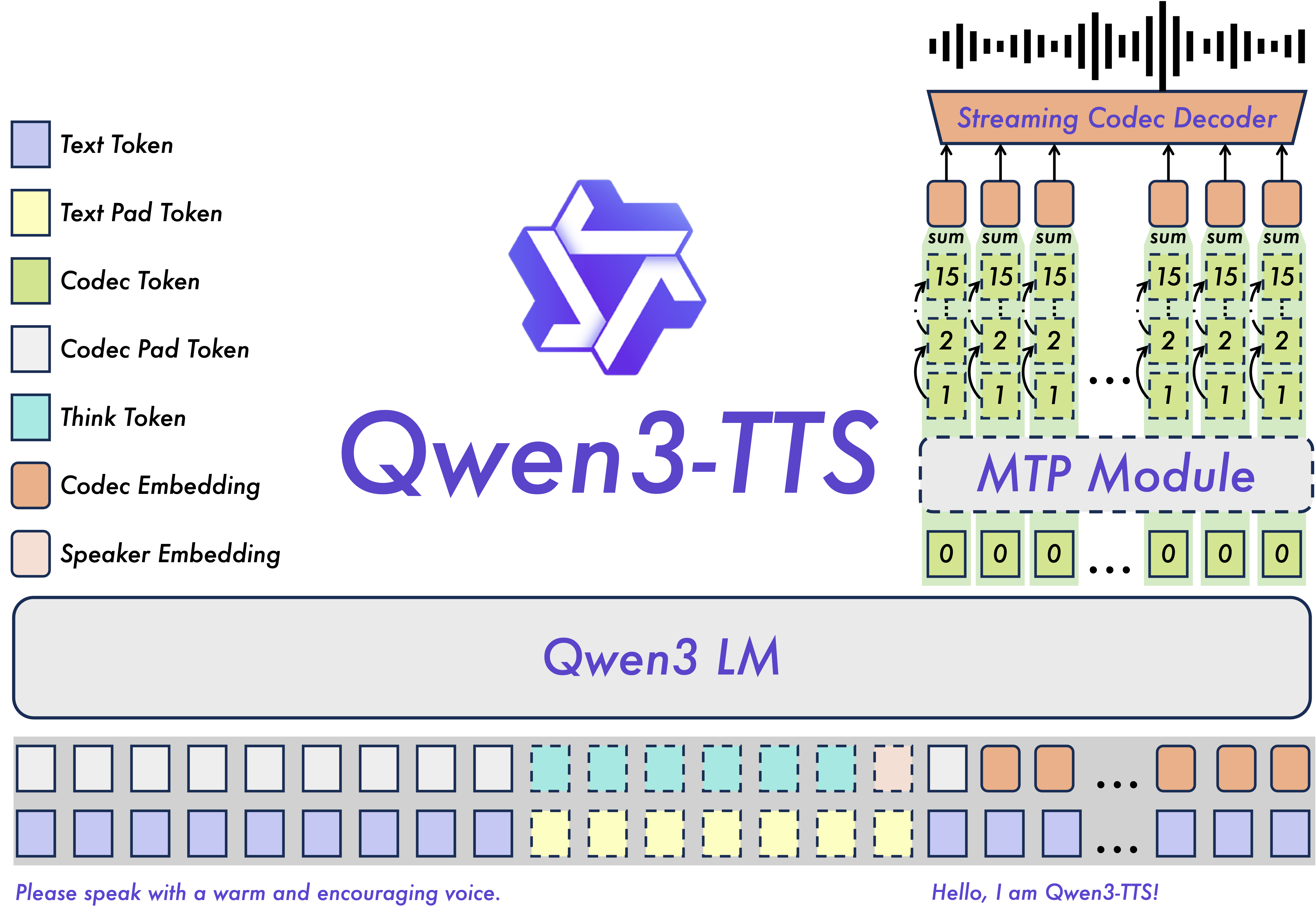
What is qwen3-tts architecture
Alibaba’s Qwen team’s TTS model family — 10 variants covering different trade-offs between quality, latency, and controllability. Open-sourced under Apache 2.0.
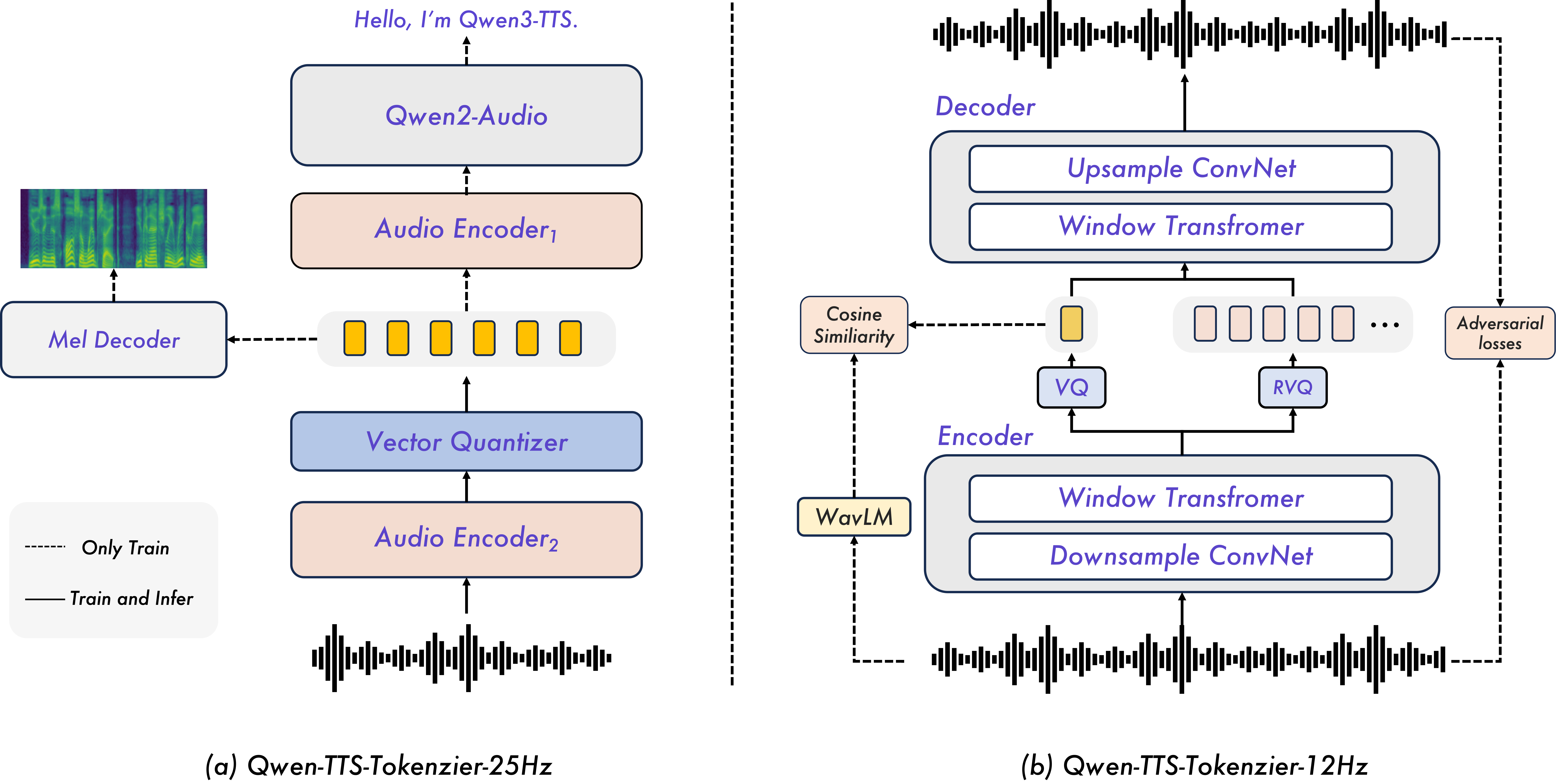
Codebooks in TTS Explained
A codebook is a fixed dictionary of sound patterns. Audio is compressed by replacing each chunk with the closest matching index in the dictionary.
Single codebook:
- One dictionary → one index per frame
- Simple, good for semantics
- Limited acoustic detail
Multi-codebook (RVQ — Residual Vector Quantization):
- Layer 1: encode audio → get index + leftover error
- Layer 2: encode the error → get index + smaller error
- Layer 3: encode that error… and so on
- Each layer adds finer acoustic detail progressively
Two Tokenizers
| 25Hz Tokenizer | 12Hz Tokenizer | |
|---|---|---|
| Codebooks | 1 (size 32768) | 16 (size 2048 each) |
| Semantic info | Strong (built on Qwen2-Audio) | First codebook only |
| LM workload | 25 predictions/sec | 12.5 predictions/sec |
| First packet | ~150ms | ~97ms |
| Best for | Long speech, quality | Ultra-low latency |
Key insight: 12Hz is faster despite 16 codebooks because the LM only handles the first codebook — a lightweight module handles the rest.
Training Pipeline
| Stage | What happens |
|---|---|
| Pre-training | 5M hours multilingual speech — learns basic text→speech mapping |
| High-quality CPT | Filtered clean data — reduces hallucinations from noisy pre-training |
| Long-context | Extends from 8k to 32k tokens — enables 10+ minute generation |
| DPO | Preference pairs from human feedback — aligns with human preferences |
| GRPO | Rule-based rewards — improves stability and task performance |
| Speaker fine-tuning | LoRA fine-tuning on specific voices — improves voice cloning |
Key Contributions
- Dual tokenizer design — one for quality, one for latency
- 5M hours training data — 5x more than Inworld
- Long-form stability — seamless 10+ minute generation without artifacts
- Voice controllability — natural language instructions for voice design
- Cross-lingual cloning — preserves voice identity across languages (e.g. zh→ko: 66% error reduction vs CosyVoice3)
- Open source — full weights + tokenizers under Apache 2.0
Voxtral TTS
What It is Mistral Voxtral?
Mistral’s multilingual TTS model with a hybrid architecture — the key innovation that sets it apart from Inworld and Qwen.
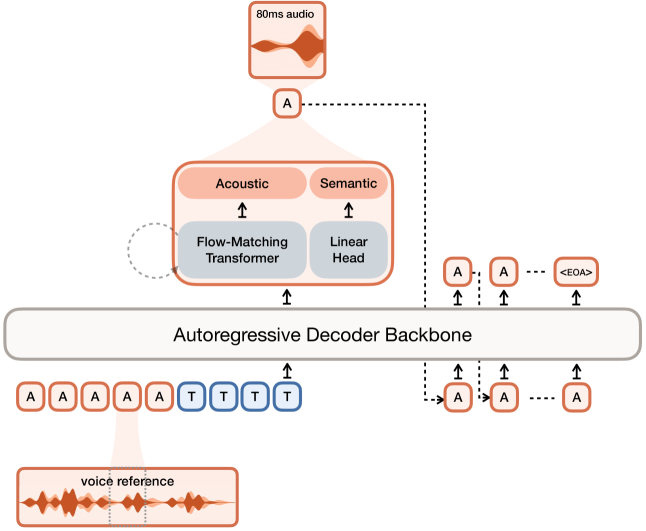
The Hybrid Architecture (The Big Idea)
Everyone else: LM generates ALL tokens autoregressively
Voxtral splits the job:
- LM (autoregressive) → generates semantic tokens (what to say, rhythm, structure)
- Flow-matching transformer → generates acoustic tokens (how it sounds, timbre, expressivity)
This is like stable diffusion but for the acoustic layer — start from noise, refine into rich audio detail in 8 steps.
Why this is clever:
- Autoregressive is great for long-range coherence
- Flow-matching is great for rich acoustic detail and expressivity
- Each component does what it’s best at
Voxtral Codec
- 12.5 Hz, 37 tokens per frame
- 1 semantic token (VQ, size 8192) — distilled from Whisper for text alignment
- 36 acoustic tokens (FSQ — Finite Scalar Quantization, not RVQ!)
- FSQ = each dimension gets quantized to 21 uniform levels independently
Training
- Pre-training on paired audio + transcripts
- DPO post-training — adapted for flow-matching (novel contribution)
Key Results
- 68.4% win rate over ElevenLabs Flash in voice cloning
- Dominant speaker similarity across all 9 languages
- Arabic specifically: 72.9% win rate 🎉
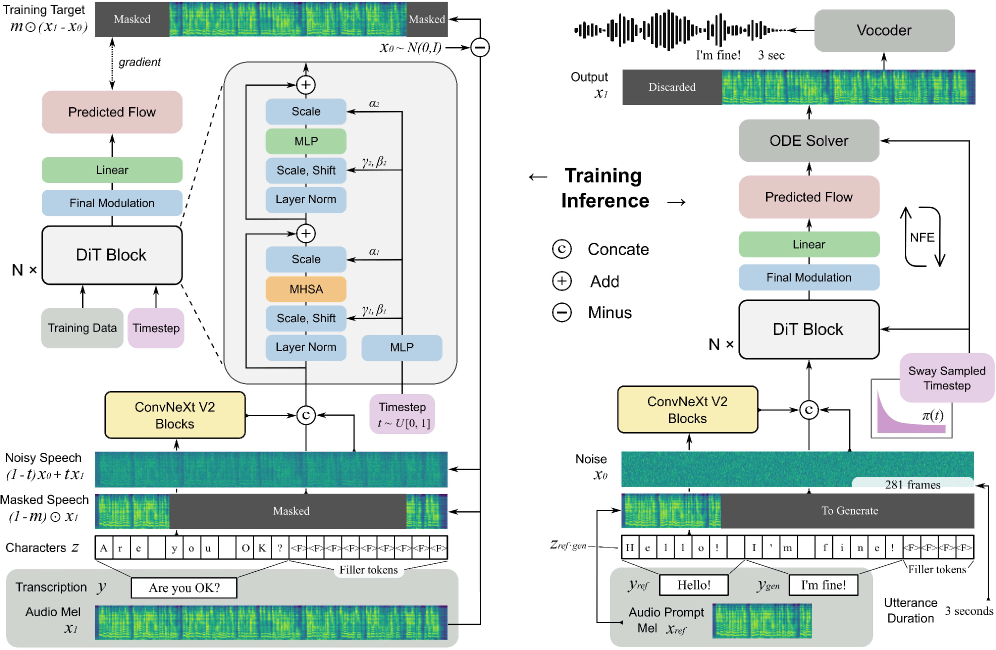
F5-TTS
What It Is
A fully non-autoregressive TTS system — no LM, no codebook, no tokenizer.
Just flow matching directly on mel spectrograms.
Architecture Comparison Across All Papers
| Inworld | Qwen | Voxtral | F5-TTS | |
|---|---|---|---|---|
| Approach | Autoregressive LM | Autoregressive LM | Hybrid AR + Flow | Pure Flow Matching |
| Codec/Tokenizer | X-codec2 | Custom dual tokenizer | Voxtral Codec | None (mel spec) |
| Text alignment | Implicit | Implicit | Implicit | Filler token padding |
| Parameters | 1.6B / 8.8B | 0.6B / 1.7B | 4B | 336M |
| Training data | 1M hours | 5M hours | Not specified | 100K hours |
F5-TTS achieves competitive results with 10x less data and a much smaller model.
Sway Sampling
During flow matching, you take steps from noise (t=0) to speech (t=1). Normally steps are uniform.
Sway Sampling biases steps toward smaller t values (early steps) — because early steps sketch the overall structure of speech (alignment, rhythm), while later steps just add detail.
\[f_{sway}(u; s) = u + s \cdot (\cos(\frac{\pi}{2}u) - 1 + u)\]
With s = -1 (sway left):
- More steps spent at the beginning → better text alignment
- Fewer total steps needed → faster inference
- RTF of 0.15 — the fastest in this paper set!
They proved this with a “leak and override” experiment: inject ground truth audio into early steps, then override with different text — with Sway Sampling the model follows the text, without it the model gets stuck on the leaked audio.
Results
On Seed-TTS test-en (WER ↓):
| Model | WER |
|---|---|
| Ground Truth | 2.06% |
| Qwen3-TTS-12Hz-1.7B | 1.24% |
| F5-TTS (32 NFE) | 1.83% |
| CosyVoice | 3.39% |
| FireRedTTS | 3.82% |
F5-TTS is competitive despite being 10x smaller and trained on 50x less data than Qwen.
Key Limitation
No fine-grained emotion/style control — it can mimic the reference voice’s emotion but can’t be instructed explicitly like Qwen or Voxtral.
References
- F5-TTS
- Voxtral Mistral
- Seed-TTS
- Qwen3-TTS
- Spark-TTS more from myside :