Meta’s RAPTOR RAG, DFloat11 Compression & Pyrefly Guide
RAPTOR RAG, rag raptor, meta pyrefly, raptor rag paper, llamaindex raptor, DFloat11, pyrefly, RAG technique, document retrieval
RAG RAPTOR, DFloat11 and Pyrefly: Meta’s Latest Open Source Tools
Over the last 2 days, I’ve been exploring some fascinating new open source tools from Meta and other organizations. These tools are revolutionizing how we approach RAG (Retrieval-Augmented Generation), model compression, and Python development. Let me break down what I’ve learned:
- RAPTOR RAG - Meta’s tree-based retrieval technique
- DFloat11 - Lossless compression for LLMs
- Pyrefly - Fast Python type checker in Rust
- FastEmbed - Efficient embedding generation
What is RAPTOR RAG? Complete Guide to Meta’s RAPTOR Technique
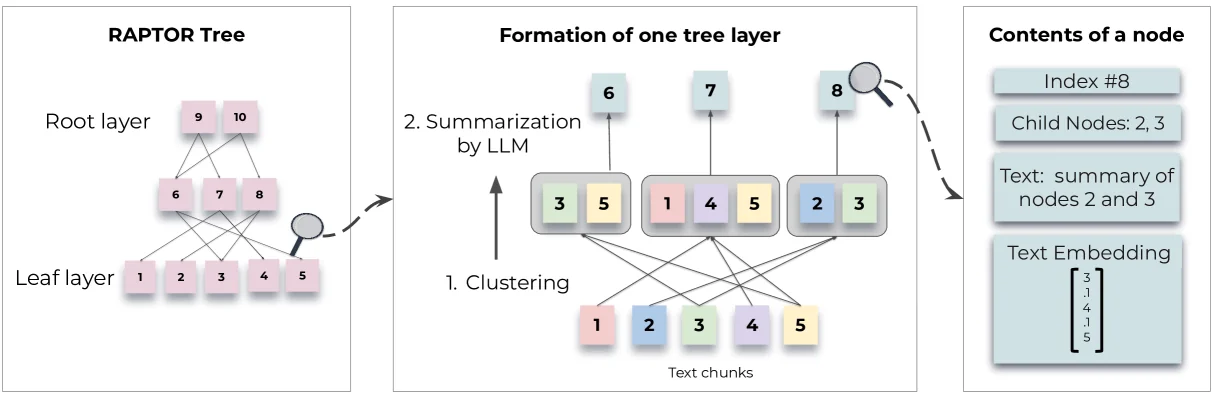
RAPTOR RAG is Meta’s innovative technique designed to improve document retrieval performance. While they claim a 20% improvement, my testing shows mixed results depending on the use case.
Understanding RAPTOR RAG
RAPTOR stands for “Recursive Abstractive Processing for Tree-Organized Retrieval.” It’s a tree-based approach that constructs hierarchical representations of your documents by recursively clustering text chunks based on their vector embeddings and generating summaries of those clusters.
The core innovation is building a tree structure from the bottom up, which helps solve the fundamental limitation of traditional RAG systems: retrieving only a few short, contiguous text chunks that limit their ability to represent large-scale discourse structure.
The Problem RAPTOR RAG Solves
Traditional RAG systems struggle with thematic questions that require integrating knowledge from multiple parts of a document. This is particularly relevant for complex queries like understanding an entire book or analyzing long-form content.
Example: Consider the fairy tale of Cinderella and the question “How did Cinderella reach her happy ending?” Traditional RAG’s top-k retrieved short contiguous texts won’t contain enough context to answer this comprehensively.
How RAPTOR RAG Works
RAPTOR solves this by using a tree structure to capture both high-level and low-level details about text. The process involves:
- Clustering text chunks based on semantic similarity
- Generating summaries for each cluster using language models
- Repeating the process recursively to build a hierarchical tree
- Tree-based retrieval during query time
Model-Based Summarization in RAPTOR
After clustering nodes using Gaussian Mixture Models, each cluster is sent to a language model (typically GPT-3.5-turbo) for summarization. This step transforms large chunks of text into concise, coherent summaries, condensing potentially large volumes of retrieved information into manageable sizes.
Querying RAPTOR RAG
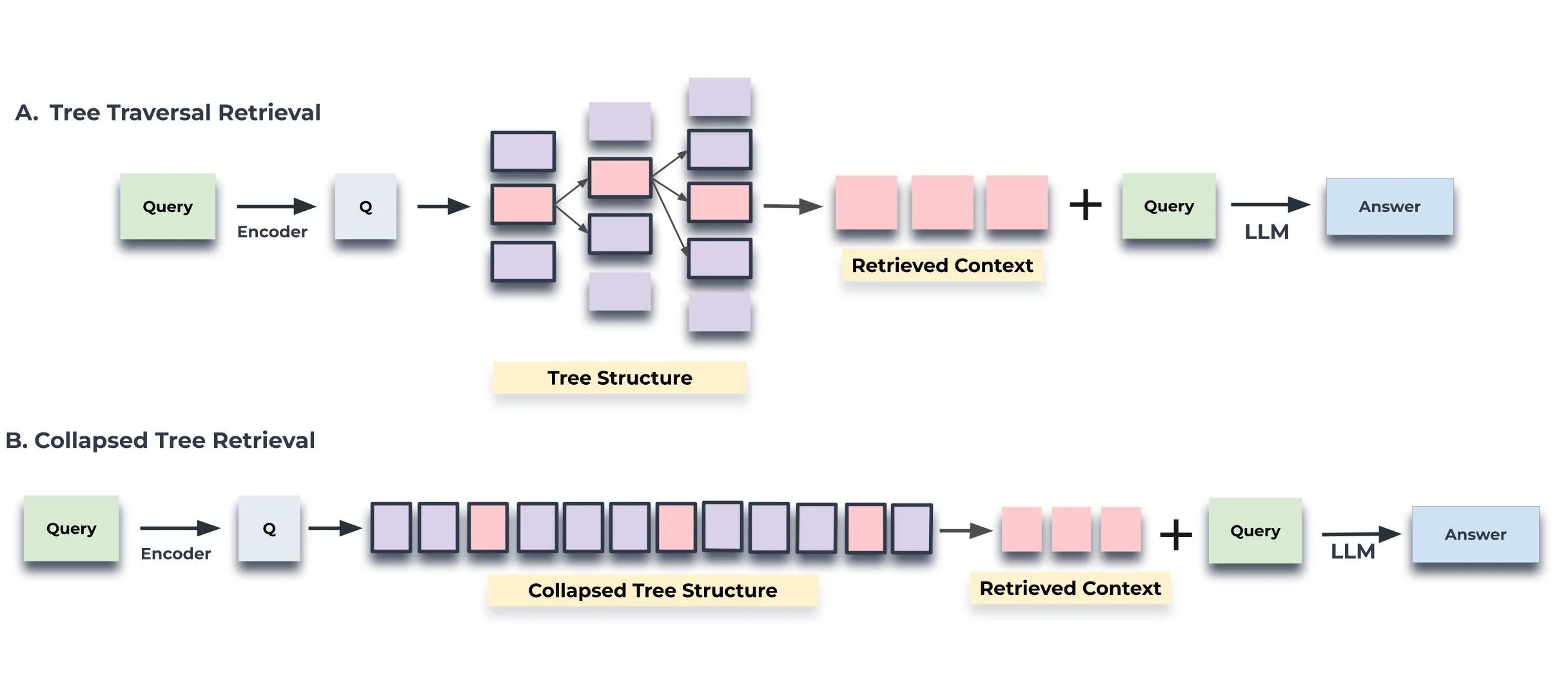
RAPTOR supports two main querying approaches:
- Tree Traversal - Navigate through the hierarchical structure
- Collapsed Tree Retrieval - Flatten the tree for faster retrieval
RAPTOR RAG Performance Analysis
While the 20% improvement claim is appealing, my testing reveals some limitations:
- Accuracy gains are marginal compared to SBERT-based solutions
- Computational overhead is significant for creation and retrieval
- Best use case is document summarization rather than question answering
- Information flow can be repetitive in some scenarios
RAPTOR RAG for Document Summarization
The most compelling use case for RAPTOR is document summarization. By having detailed, medium, and high-level information representations, you can create better summaries by:
- Dividing the summarization task across multiple levels
- Pre-computing summaries at different granularities
- Reducing the burden on the final LLM for summary generation
DFloat11: Efficient, Lossless Compression for LLMs
DFloat11 (DF11) is a novel, mathematically lossless compression technique that reduces large language model memory usage by about 30% with zero accuracy loss. Unlike traditional quantization methods that can degrade model quality, DF11 uses Huffman coding to compress only the predictable exponent bits of model weights.
How DFloat11 Works
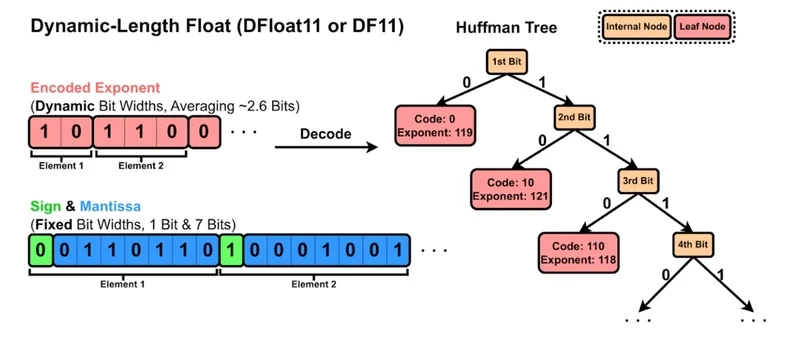
DFloat11’s compression strategy is elegant in its simplicity:
- Sign and Fraction Bits: Kept unchanged as they contain high-entropy information
- Exponent Bits: Compressed using a precomputed Huffman tree, replacing the fixed 8-bit exponent with variable-length codes
- Average Savings: About 5 bits per weight on average
DFloat11 Storage and Decoding
Storage Architecture: - Sign/fraction and exponent bits stored separately - Small header containing the Huffman codebook - Efficient packing for minimal overhead
Runtime Decoding: - Original weights quickly reconstructed by combining sign/fraction block with decoded exponent - Enables fast, parallel processing on GPUs - No performance penalty during inference
DFloat11 Key Benefits
- 30% reduction in model size compared to bf16
- 100% identical accuracy to the original model
- Universal applicability to any transformer-based LLM
- Zero training required - works with existing models
Pyrefly: Fast Python Type Checker in Rust
Pyrefly is a blazingly fast Python type checker written in Rust, designed to provide near-instantaneous type checking for large Python codebases.
Installing Pyrefly with VS Code
I installed Pyrefly into VS Code and tested it with several projects including LlamaIndex and TypeCodebase. The experience was impressive:
- Lightning-fast type checking compared to traditional tools
- Seamless VS Code integration with real-time feedback
- Excellent performance on large codebases
- Rust-powered reliability with minimal memory usage
Pyrefly vs Traditional Type Checkers
Pyrefly’s Rust implementation provides significant advantages:
- Speed improvements of 10-100x over Python-based type checkers
- Lower memory footprint for large projects
- Better error reporting with precise location information
- Incremental checking for faster subsequent runs
LlamaIndex RAPTOR Integration
For those using LlamaIndex, RAPTOR RAG can be integrated to improve document retrieval performance. The tree-based approach works particularly well with LlamaIndex’s document processing pipeline.
Implementation Considerations
When implementing RAPTOR with LlamaIndex:
- Consider the computational cost of building the tree structure
- Evaluate performance gains for your specific use case
- Test with your document types before full deployment
- Monitor memory usage during tree construction
Meta Pyrefly and Open Source Ecosystem
Meta’s contribution to the Python development ecosystem through Pyrefly demonstrates their commitment to developer productivity. The combination of Rust’s performance with Python’s flexibility creates a powerful tool for modern development workflows.
Conclusion
These three tools represent significant advances in their respective domains:
- RAPTOR RAG offers a novel approach to document retrieval, though with mixed practical benefits
- DFloat11 provides genuine value for LLM deployment with lossless compression
- Pyrefly delivers substantial performance improvements for Python type checking
While RAPTOR RAG’s claims may be overstated, the underlying tree-based approach shows promise for specific use cases like document summarization. DFloat11 and Pyrefly, however, offer clear, measurable benefits that make them valuable additions to any ML or Python development toolkit.
References
- XMad Team Blog - Meta’s research team insights
- RAPTOR Paper - Original research paper
- Pyrefly Official Site - Documentation and installation
- DFloat11 Research - Compression technique details
- LlamaIndex Documentation - RAG framework integration
Internal Resources
If you’re interested in more about AI engineering and my research, explore these sections: